
为了描述或测试人口的假设,对一小部分人口进行取样通常比对整个人口进行普查更可取。与进行人口普查相比,采取样本通常更便宜,耗时较少,因为可以花费更多的精力和护理,以确保以正确的方式收集正确的数据。适当收集的数据可用于推断整个人群。
采样技术可以分为非概率样本和概率样本。选择概率样本的方式是,几乎所有人口的成员都有非零的概率被包括在内,并且该概率是已知或可计算的。非概率样本的收集方式不取决于机会。这意味着很难或不可能估计包括特定人口单位的可能性。此外,通常排除了很大一部分人口。因此,样本的质量取决于研究人员的知识和技能。
通常,概率样本比非概率样本更可取,因为可以使用统计技术将结果推广到整个种群。这种概括通常没有非概率样本无效,因为将部分人口排除在抽样之外,意味着结果可能会偏差。例如,自愿参加研究的人可能与没有不同的人不同。它们的年龄,性别,职业,动机或可能与研究有关的任何其他特征可能有所不同。如果该研究涉及态度或观点,那么志愿者参与者可能对这些问题有不同的感觉,并且通常比非参与者更强烈。
但是,非概率样本具有其优势和用途。它们相对容易且价格便宜。它们对于探索性研究或研究人员想要记录范围或提供特定示例而不是研究趋势或因果过程时可能很有价值。此外,最近已经开发了从某些类型的非概率样本中获得无偏见结果的技术。
Two concepts are important to sampling in general: the target population and the sampling frame. The target population is the population to which the researcher wants to generalize the findings. One important characteristic of the population is the kind of entities its members are, known as the unit of analysis. The cases in the sample correspond to this unit of analysis. Examples of a unit of analysis are the individual, the organizational department, the organization, or some geographical unit, such as the state. The unit of analysis is characterized by a set of attributes on which the researcher gathers data. These are the variables the researcher scores for each case in the sample. For example, a researcher might explore individual characteristics such as age or years of education. Usually, the target population is circumscribed by some characteristic or combination of characteristics. It may be employees of a particular firm, or there may be a geographical limitation, such as residents of a particular city. Constraints on gender, ethnicity, age-group, work status, or other characteristics may be specified as well. A target population, for example, might be permanent, full-time female employees of a particular company.
The sampling frame is the complete list of all units from which the sample is taken. For the target population of permanent, full-time female employees, for example, the sampling frame might be a list of permanent, full-time female employees from all of the company’s locations. For telephone surveys, a list of phone numbers is a typical sampling frame, perhaps for particular area codes or in conjunction with block maps.
概率样本
样品设计
For probability samples, there are four common designs: the simple random sample, the systematic sample, the stratified sample, and the cluster sample. A simple random sample is drawn in such a way that every combination of units of a given size has an equal probability of being drawn. If there are n individuals in the sample and N in the population, for example, each individual’s probability of being included is n/N. The simple random sample is optimal for estimating unbiased population characteristics as precisely as possible. The most commonly used statistical techniques assume and work best with simple random samples. A simple random sample can be drawn by applying a table of random numbers or pseudorandom numbers generated by a computer to the sampling frame. Unfortunately, for many target populations, it is difficult and costly to draw a simple random sample. Hence, researchers use sample designs that approximate simple random samples.
这样的设计是一个系统的样本,其绘制的方式使目标人群中的每个单元都具有相同的选择概率,但是对于给定尺寸的单元组合的每个组合都不是相同的。当样本框架为长,未计算的列表时,可以使用系统样本。要执行它,请根据所需的样本尺寸(n)确定采样间隔(i):i = n/n。从列表中的第一个单元中随机选择一个起始情况。然后从起始情况下选择每个ITH单元。除非采样框架中有某种周期性,否则系统样本将近似一个简单的随机样本,然后会导致结果偏差。
分层样本是更受控的采样设计,该样本是为了确保样本中不同人群群体的特定比例表示。例如,如果目标人群为10%的西班牙裔人,那么从人群中抽出的简单随机样本可能会超过10%的西班牙裔。分层样本可确保有10%的样本(或其他所需的比例(例如20%))将是西班牙裔。分层样品可以分为成比例和不成比例的样本。比例的分层样品可确保样品的组成反映了沿变量或变量组合的种群的组成。要执行它,请根据所需的方面将目标人群分为亚组 - 例如,他的甲壳虫和非西班牙裔。然后从每个子组中获取一个简单的随机样本,每个子组的选择概率相同。
在不成比例的分层样本中,样本中不同亚组的比例与目标群体不同。通常,样品的组成代表仅形成一小部分人群的亚组。目的是改善该亚组的估计值,并改善亚组之间的比较。例如,假设样本量为500,目标人群为5%的西班牙裔。一个简单的随机样本将包括大约25个西班牙裔个体,这太小了,无法获得该亚组的精确估计。如果需要更好的估计,则可以提高样本中西班牙裔的比例,例如20%,这将确保选择100个西班牙裔人,从而为亚组产生更精确的估计,并允许西班牙裔和非西班牙裔人成为比较更准确。应使用权重进行整个样本的分析,以调整某些亚组的过度代表性,这是计算机的大多数主要统计包中的简单选择。
Cluster sampling is a common method for face-to-face data collection such as surveys. The data are gathered from a small number of concentrated, usually spatially concentrated sets of units. A few departments of an organization may be sampled, for example, or a few locations if an organization has multiple locations. Cluster sampling may be chosen to reduce costs or because there is no adequate sampling frame from which a simple random sample or systematic sample could be drawn.
Sample Size
研究中通常出现的一个问题是样本需要多大。收集数据是昂贵的,如果可能的话,最好专注于从较小样本中收集较高质量的数据。有几种估计必要样本量的方法。一种方法只是使用近似其他高质量研究的样本量。一些参考文献包含提供适当样本量的表。
Two formulas may be of assistance. Let p denote the proportion of the population with a key attribute; if the proportion is unknown, p = .5 (which assumes maximum variability) may be used. Let e denote the sampling error or level of precision, expressed as a proportion. Thus, e = .05 means ± 5% precision. Finally, suppose a confidence level of 95% is desired. The sample size, n0, may be estimated by
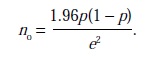
If the key variable takes on more than two values, the best method may be to dichotomize it—that is, transform it into a variable that takes two values—and then estimate p. Otherwise, p =.5 may be used, which gives a conservative estimate of sample size. For smaller populations (in the thousands, for example), wherein population size is denoted by N, the formula
![]()
可能用过了。
Other considerations may also affect the determination of the necessary sample size. If the researcher wishes to analyze subgroups of the target population separately or compare subgroups, then the sample must be large enough to represent each subgroup adequately. Another concern is nonresponse. Inevitably, not all units in the selected sample will provide usable data, often because they refuse or are unable to participate but also because of respondent error. Here, too, the sample must be large enough to accommodate nonresponses and unusable responses. Finally, money and time costs are a constraint in sampling and should be considered in planning the study so that the sampling can be completed as designed.
非概率样本
随意,方便,配额和有目的的样本是最常见的非概率样本。便利样本包括自我选择的单位(例如志愿者)或易于访问。便利样本的例子是自愿参加研究的人,当人口包含多个地点的人和雪球样本时,在给定位置的人。雪球或受访者驱动的样本是研究人员从某些被称为“种子”的受访者开始的样本,然后通过以前的受访者获得更多受访者。配额样本是选择具有某些特征的预定数量的单元。对于目的样本,根据对评估很重要的特性或属性选择单位。许多焦点小组是这种样本。
最近,在获得无法直接绘制概率样本的人群的无偏见结果方面取得了进步,通常是因为没有足够的抽样框架可用。超网络方法可以应用于与人相关的对象或活动的目标人群,例如艺术对象或与艺术相关的活动。然后,可以使用个人的概率样本来获取提供这些对象或活动的组织的概率样本。另一种方法再次使用社交网络分析的技术来从受访者驱动的样本中获得无偏的估计。此方法特别有助于估计隐藏人群的特征,例如在特定位置的无家可归者或吸毒者。
参考:
- Cochran,W。G.(1977)。采样技术。纽约:威利。
- Kish,L。(1965)。调查抽样。纽约:威利。McPherson,M。(2001)。艺术的采样策略:超网络方法。诗学,28,291-306。
- Miaoulis,G。和Michener,R。D.(1976)。抽样简介。IA迪比克:肯德尔/亨特。
- Salganik,M。J.和Heckathorn,D。(2004)。使用受访者驱动的抽样中隐藏群体的采样和估计。社会学方法论,34,193-240。